Using XML Frame Statistics
January 2006
![]()
Using XML Frame StatisticsJanuary 2006 |
|
Starting with Release 13 of PhotoRealistic RenderMan, per-frame statistics are output in a simple XML format. A stylesheet allows the results to be viewed in a Web browser. Customized queries and reports can be implemented with modest effort using a variety of off-the-shelf XML technologies.
Statistics output is controlled by the following RIB options:
Option "statistics" "endofframe" [ N ]
Option "statistics" "filename" [ "filename.txt" ]
Option "statistics" "xmlfilename" [ "filename.xml" ]
where N is either 0 or 1. (Values greater than 1 are permitted, but do not
increase the level of detail. The level of detail is now controlled by
post-processing the XML file.)
A brief plain-text summary of the statistics is written to one file, while a full XML report is written to another file. Statistics are no longer accumulated in the output file from one render to the next.
Either filename may be the empty string, which disables that kind of output, or "stdout", in which case the output is displayed on the console. (Note that XML written to stdout might not be well formed if procedural or shader plugins also write to stdout.) The default values of "filename" is "stdout", and the default value of "xmlfilename" is the empty string. These defaults can be changed by editing the RenderMan configuration file (etc/rendermn.ini).
The "xmlfilename" can be set to a special value, "usefilename", which indicates that XML statistics should be written to the filename that would normally receive the plain-text statistics. Doing so can facilitate incorporating XML statistics into pipelines without requiring changes to RIB generators.
To browse the statistics, simply load the .xml file into your Web browser. By default, it is linked to a stylesheet that generates an interactive report like the following:
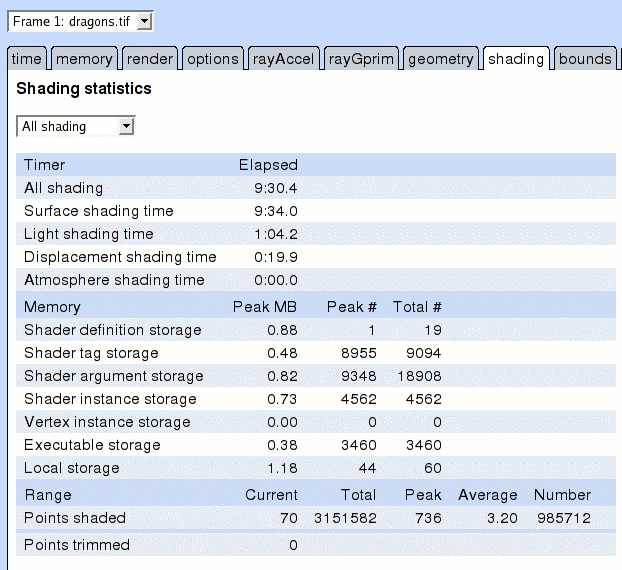
JavaScript should be enabled for best results. The default statistics stylesheet is supported by Internet Explorer 6, Netscape 7, Firefox, and Safari.
The XML file contains an <xml-stylesheet> tag that specifies the location of a stylesheet. Sometimes the Web browser is unable to locate the stylesheet. This commonly occurs if the statistics are generated on a renderfarm but viewed on workstation that does not have the stylesheet in the same location.
The location of the XML stylesheet can be specified by the following RIB option:
Option "statistics" "stylesheet" [ "URL" ]
The URL can be relative (e.g. a filename). See Section 4 for
more information on creating a custom stylesheet.
Alterntively, the location of the stylesheet can be specified in the rendermn.ini configuration file, which is located in the etc subdirectory of the RenderMan installation directory. Administrators of large installations may find it convenient to copy the default stylesheet to a central location (e.g. a Web server) and update rendermn.ini to reference that location:
/prman/statistics/stylesheet http://megacorp.com/render/style.xml
However, beware that "cross-domain security" featuers in some browsers
do not permit an XML file to use a stylesheet in a different domain
(e.g. if the XML is loaded from the local filesystem, the stylesheet
cannot be loaded from a web server).
The default stylesheet is normally located in $RMANTREE/etc/html where $RMANTREE is the location of the RenderMan installation directory. The current stylesheet filename is rmStatsHtml_1.1.xml, but subsequent releases will likely use a different version number.
If necessary, an offline processor can be used to convert the statistics XML to HTML using a stylesheet. This allows statistics to be viewed in Opera and older versions of other Web browsers.
To convert the statistics XML file to HTML, use a command-line XSLT processor like xsltproc, which is distributed with libxslt (http://xmlsoft.org/XSLT). See the XSLT FAQ for other tools (http://www.dpawson.co.uk/xsl/xslfaq.html).
The statistics XML file can be converted to text using a Python script, statsinfo.py, which resides in the same directory as the prman executable (i.e. $RMANTREE/bin). By default it shows summary timing and memory usage informtion:
> statsinfo.py stats.xml
Timer summary: elapsed
Total time: 3:48.0
All procedurals: 0:00.0
All shading: 2:42.9
Displacement shading time: 0:00.0
Surface shading time: 2:41.8
Atmosphere shading time: 0:00.0
Light shading time: 0:00.2
Memory summary: peak MB
Ray accelerator memory: 3.39
Traceable prim memory: 8.44
GUT caches: 60.00
Grid memory: 8.17
GPrim memory: 5.27
Static GOP memory: 1.90
Dynamic GOP memory: 3.19
Vertex vector memory: 19.72
Trim curve memory: 7.16
Total shading storage: 24.31
Visible points storage: 0.99
Micropolygon storage: 3.57
The entire XML file can be converted to text using the -a command-line
argument (see the statsinfo.py man page for more information).
This is often useful for writing simple scripts that extract specific
statistics. More sophisticated scripts should read the XML file
directly, as described in Section 5.
A statistics file can be compared to baseline statistics from a previous render using the statsdiff.py script:
statsdiff.py stats.xml baseline.xml > diff.xml
or alternatively,
statsdiff.py -o diff.xml stats.xml baseline.xml
After running the script, simply load the output into a Web browser to view the differences. The output is simply a copy of the input statistics with a "delta'' attribute in each XML node that differs, which is displayed as a percentage by the XML stylesheet.
By default, differences of less than 2% are ignored. The difference threshold can be specified using the "-t" comand-line argument. The threshold is typically a value between 0 and 1; for example a 5% difference threshold would be specfied as follows:
statsdiff.py -t .05 stats.xml baseline.xml > diff.xml
For more information, see the statsdiff.py man page.
RenderMan plugins (DSOs) can include timing and memory statistics in the statistics XML file using the RixStats interface. In a shader plugin this is accomplished as follows: (in a procedural plugin, use RxGetRixInterface)
#include "RixInterfaces.h"
float timeInSeconds;
RixStats* rixStats = (RixStats*) rslContext->GetRixInterface(RslContext::k_RixStats);
rixStats->AddTimerStat(&timeInSeconds, "myTimer", "My plugin timer");
The AddTimerStat method takes a pointer to a float into which the plugin records timing information (in seconds), along with a name (which must be a valid XML token) and a description (which may be empty). AddMemoryStat is similar, except that it takes a pointer to a size_t value into which the plugin records memory usage (in bytes). A duplicate call with the same name as a previously added statistic is ignored (a warning is generated if a different pointer is specified).
Note that shader plugins must take care to ensure thread safety when recording statistics in global variables. Controlling access with a mutex is straightforward. Alternatively, statistics can be recorded in per-thread data and then combined at the end of a frame. See the RSL Plugin application note or the reference documentation for RslContext::SetThreadData for more information.
A plugin can also report arbitrary information in the statistics XML file by registering a reporting function using the AddReporter method of RixStats:
void AddReporter(Reporter func);
Duplicate registrations of the same reporting function are ignored. If
statistics are enabled, registered reporting funtions are called at the end of
each frame, after the built-in statistics are reported.
A statistics reporter is a function with the following prototype:
void myReporter(RixXmlFile* file) { ... }
The reporting function is given an RixXmlFile
object, which can be written using the following
methods:
void WriteXml(char* format, ...);
void WriteText(char* format, ...)
Conceptually, these methods operate like printf. The WriteXml method should be used when writing XML tags, attributes, and numeric values. The WriteText method should be used when writing other values, since XML requires certain characters to be encoded (e.g. < is encoded as <). For example:
void myReporter(RixXmlFile* file)
{
file->WriteXml ("<stats name=\"myPlugin\">\n");
file->WriteXml (" <int name=\"count\"> %i </int>\n", myCounter);
file->WriteXml (" <string name=\"info\">\n");
file->WriteText(" %s\n", myInfo);
file->WriteXml (" </string>\n");
file->WriteXml ("</stats>\n");
}
Reporting functions should generate XML that matches the format described below, otherwise the default XML stylesheet (and future utilities) will not operate properly.
Here is a greatly simplified example of a statistics file:
<rm:statsDoc>
<stats name="system">
<int name="maxMem">130392040</int>
<timer name="totalTime">
<elapsed>19.5</elapsed>
<user>19.1</user>
<system>0.3</system>
</timer>
</stats>
<stats name="options">
<string name="timestamp">Wed Jan 04 12:53:44 PST 2006</string>
<stats name="displaylist">
<stats name="display">
<string name="name">dragons.tif</string>
<string name="type">framebuffer</string>
<string name="mode">rgba</string>
</stats>
</stats>
</stats>
</rm:statsDoc>
Whenever possible, you should not rely on the overall layout of a statistics file. For example, the following aspects of the format may change with each RenderMan release:
What can you rely upon? The next section gives an exact answer. Informally, you can rely upon the following:
Despite these restrictions, it is relatively straightforward to write a report generator that processes statistics in a generic way (see Section 4). Querying particular statistics requires certain compromises; see Section 4 for further discussion.
The format of statistics XML files is formally specified by an XML Schema. The current XML schema is located at http://renderman.pixar.com/schema/rmStats_1.1.xsd. (It may be superseded by newer versions.) For more information on XML Schema in general, see http://www.w3.org/TR/xmlschema-0. This section summarizes the statistics schema in human-readable form (a BNF grammar).
Stats: <stats Name> Stat* </stats>This indicates that a <stats> element includes some attributes (specified by the Name rule) and contains zero or more individual statistics (specified by the Stat rule).
An XSLT stylesheet consists of a sequence of templates that specify how to transform XML to HTML or some other format. For example, here is a template that specifies how to format a <timer> statistic. (Some additional boilerplate is required; see Appendix A for a complete listing.)
<xsl:template match="timer">
<xsl:value-of select="elapsed"/> seconds
</xsl:template>
The xsl:value-of construct is used to select the <elapsed> member of the <timer> (any <user> and <system> tags are discarded).
Here is a recursive template that describes how a <stats> list is converted to an HTML list:
<xsl:template match="stats">
<ul>
<xsl:for-each select="*">
<li>
<xsl:value-of select="@description"/>:
<xsl:apply-templates select="."/>
</li>
</xsl:for-each>
</ul>
</xsl:template>
Note that the desired HTML output tags are intermingled with XSLT instructions. This template matches any <stats> tag and generates a list enclosed in <ul> ... </ul>. The xsl:for-each construct iterates over the items in the <stats> list. Matching <li> ... </li> are generated for each item in the <stats> list. Each item in the HTML list contains the description attribute of a statistic, followed by whatever HTML is generated by other templates for that kind of statistic.
This example requires some refinement, since the description attribute of a statistic is optional. In such cases the output should use the name attribute instead. We can encapsulate this behavior in an XSLT function and replace
<xsl:value-of select="@description"/>
with
<xsl:call-template name="Description"/>
A function is declared like a template, but with a name attribute instead of a match attribute:
<xsl:template name="Description">
<xsl:choose>
<xsl:when test="@description != ''">
<xsl:value-of select="@description"/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="@name"/>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
This function takes no arguments, but it has complete access to the current XML node. Note that if/then/else is expressed rather clumsily in XSLT:
Additional templates are necessary to handle structured statistics, like <memory> and <histogram> (see Appendix A for a complete listing). Simple statistics like <int> and float can be handled by a default template that simply reports the value of the statistic (the description of the statistic was reported by the <stats> template above).
<xsl:template match="*">
<xsl:value-of select="."/>
</xsl:template>
Python is well suited to handling XML. It's easy to load an XML document using the minidom package:
from xml.dom import minidom, Node
docNode = minidom.parse("filename.xml").documentElement
This yields a Node object whose members include:
def getChildren(node):
"Return the child elements of the given XML node"
return filter(lambda child: child.nodeType == Node.ELEMENT_NODE,
node.childNodes)
Getting the text of a node is also a common operation. Here's a fairly
general way to do it that handles nodes with multiple child text nodes:
def getText(node):
""" Returns the stripped text of the given node. Multiple text nodes
are striped and joined by spaced. """
return " ".join( [child.data.strip() for child in node.childNodes
if child.nodeType == Node.TEXT_NODE] )
Given those functions, here's a simple way to print a statistics XML file in
Python:
from xml.dom import minidom, Node
import sys
def printf(format, *args):
sys.stdout.write(format % args)
def printStats(filename):
root = minidom.parse(filename).documentElement
for child in getChildren(root):
printStat(child)
def printStatsList(node, depth=0):
printf("%s%s:\n", depth * " ", node.attributes["name"].value)
for child in getChildren(node):
printStat(child, depth+1)
def printStat(node, depth=0):
if node.nodeName == "stats":
printStatsList(node, depth+1)
else:
printf("%s%s: ", depth * " ", node.attributes["name"].value)
if node.nodeName in ["int", "float", "string"]:
printf("%s\n", getText(node))
else:
printf("\n");
for child in getChildren(node):
printf("%s%s: %s\n", (depth+1) * " ",
child.nodeName, getText(child))
A more refined approach is to convert the XML into a tree of statistics and then write methods that traverse the tree. Each node in the tree will be an object that holds the components of a statistic in its members. Each kind of statistic has a name and optional description, so it's natural for them to inherit from a common base class:
class Stat(object):
name = ""
description = ""
class IntStat(Stat):
value = 0
class FloatStat(Stat):
value = 0.0
class TimerStat(Stat):
elapsed = 0.0
user = None # optional
system = None # optional
(This is a partial listing; see Appendix B for a complete listing.)
Each of these classes can define an initialization method that constructs the object from an XML node:
class Stat(object):
def __init__(self, node):
self.name = node.getAttribute("name")
self.description = node.getAttribute("description")
class IntStat(Stat):
def __init__(self, node):
Stat.__init__(self, node)
self.value = int(getText(node))
class FloatStat(Stat):
def __init__(self, node):
Stat.__init__(self, node)
self.value = float(getText(node))
class TimerStat(Stat):
def __init__(self, node):
Stat.__init__(self, node)
vals = [float(getText(child)) for child in getChildren(node)]
self.elapsed = vals[0]
if len(vals) > 1:
self.user = vals[1]
self.system = vals[2]
A <stats> list also derives from the Stat base class, but it also derives from the built-in list class. It looks up the nodeName of each child in a dictionary to determine which type of object to construct for that child:
class StatsList(list, Stat):
def __init__(self, node):
Stat.__init__(self, node)
nodeTypes = { "int" : IntStat,
"float" : FloatStat,
"timer" : TimerStat,
"stats" : StatsList
# ... and more...
}
for child in getChildren(node):
self.append( nodeTypes[child.nodeName](child) )
Finally, a <statsDoc> can be handled just like a <stats> list, since it contains an arbitrary list of statistics. For convenience, let's have the initialization function take a filename and call the minidom XML parser:
class StatsDoc(StatsList):
def __init__(self, filename):
docNode = minidom.parse(filename).documentElement
StatsList.__init__(self, docNode)
Representing statistics as a tree of objects rather than an XML tree has numerous advantages. Tree traversals can be implemented by recursive methods. For example, each class can define a write method that outputs the object as XML:
import sys
def printf(format, *args):
sys.stdout.write(format % args)
class IntStat(Stat):
def write(self):
printf('<int name="%s">%i</int>', self.name, self.value)
class StatsList(list, Stat):
def write(self):
printf('<stats name="%s">\n', self.name)
for child in self:
child.write()
printf("\n")
printf("</stats>")
It's also much easier to perform transformations on trees of statistics instead of XML trees. For example, summing the per-frame statistics of a render is relatively straightforward.
C programmers have many XML libraries from which to chose. libxml2 is a good choice (http://xmlsoft.org) because it's portable, includes XPATH, and integrates well with libxslt (http://xmlsoft.org/XSLT).
Here is some sample code that shows how to convert a statistics XML file to plain text. (See Appendix C for a complete listing.) The XML file is parsed as follows, yielding a <statsDoc> node.
int main(int argc, char** argv) {
/* NOTE: error checking omited for brevity. */
doc = xmlParseFile(argv[1]);
xmlNodePtr root = xmlDocGetRootElement(doc);
printStatsDoc(root); /* defined below */
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
}
void printStatsDoc(xmlNodePtr node) {
for (node = node->children; node != NULL; node = node->next)
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE)
printStatsList(node, 0);
}
A <stats> list has a name attribute, which is extracted via xmlGetProp() (which returns a string that must be freed via xmlFree()). After printing the name of the <stats> list, we print the children with nested indentation:
void printStatsList(xmlNodePtr node, int depth) {
xmlChar* name = xmlGetProp(node, "name");
indent(depth); printf("%s:\n", name);
xmlFree(name);
for (node = node->children; node != NULL; node = node->next)
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE)
printStat(node, depth+1);
}
A <stats> list contains individual stats, along with nested <stats> lists. We use the element name (e.g. <int>, <float>, etc.) to decide how to proceed:
void printStat(xmlNodePtr node, int depth) {
/* Recursively print any nested stats lists. */
if (!xmlStrcmp(node->name, "stats")) {
printStatsList(node, depth+1);
return;
}
/* Print the name of the stat. */
xmlChar* name = xmlGetProp(node, "name");
indent(depth); printf("%s: ", name);
xmlFree(name);
if (!xmlStrcmp(node->name, "int") ||
!xmlStrcmp(node->name, "float") ||
!xmlStrcmp(node->name, "string")) {
printContent(node);
printf("\n");
}
else
printStructuredStat(node);
}
Simple statistics contain text that is fetched with xmlNodeListGetString() (note that it requires a pointer to the top of the XML document, which we hold in a global variable).
void printContent(xmlNodePtr node) {
xmlChar* text = xmlNodeListGetString(doc, node->children, 1);
printf("%s", text);
xmlFree(text);
}
Structured statistics like <timer> have a nested element for each member. These can be handled generically as follows:
/* Print a structured stat that has simple members. */
void printStructuredStat(xmlNodePtr node) {
int first = 1;
for (node = node->children; node != NULL; node = node->next) {
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE) {
if (!first) printf(", ");
else first = 0;
/* Print the member name and text. */
printf("%s: ", node->name);
printContent(node);
}
}
printf("\n");
}
Alternatively, since the format of structured statistics is described in the XML Schema, it's safe to access the children by position.
void printMemoryStat(xmlNodePtr node, int depth) {
/* Skip child text nodes, which contain only whitespace. */
xmlNodePtr peak = nth(node->children, 0);
xmlNodePtr current = nth(node->children, 1);
printf("peak: "); printContent(peak);
printf("current: "); printContent(current);
printf("\n");
}
/* Get the nth element in a sequence of nodes, ignoring any text nodes. */
xmlNodePtr nth(xmlNodePtr node, int n) {
while (node) {
if (node->type != XML_ELEMENT_NODE)
node = node->next;
else if (n == 0)
return node;
else {
--n;
node = node->next;
}
}
return NULL;
}
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0"
xmlns:rm="http://renderman.pixar.com"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/rm:statsDoc">
<html>
<body>
<xsl:apply-templates select="*"/>
</body>
</html>
</xsl:template>
<xsl:template match="stats">
<ul>
<xsl:for-each select="*">
<li>
<xsl:call-template name="Description"/>:
<xsl:apply-templates select="."/>
</li>
</xsl:for-each>
</ul>
</xsl:template>
<xsl:template match="timer">
<xsl:value-of select="format-number(elapsed, '0.0')"/> s
</xsl:template>
<xsl:template match="memory">
<xsl:variable name="megs" select="peak div (1024*1024)"/>
<xsl:value-of select="format-number($megs, '0.00')"/> M
</xsl:template>
<xsl:template match="range">
current <xsl:value-of select="current"/>,
total <xsl:value-of select="total"/>,
max <xsl:value-of select="max"/>
</xsl:template>
<xsl:template match="histogram">
<table border="1" cellpadding="2" cellspacing="0">
<tr>
<xsl:for-each select="*">
<td align="center" width="25">
<xsl:value-of select="@label"/>
</td>
</xsl:for-each>
</tr>
<tr>
<xsl:for-each select="*">
<td align="right">
<xsl:value-of select="."/>
</td>
</xsl:for-each>
</tr>
</table>
</xsl:template>
<xsl:template match="set">
<xsl:for-each select="*">
<br/>
<xsl:value-of select="."/>
</xsl:for-each>
</xsl:template>
<xsl:template match="*">
<xsl:value-of select="."/>
</xsl:template>
<xsl:template name="Description">
<xsl:choose>
<xsl:when test="@description != ''">
<xsl:value-of select="@description"/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="@name"/>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
import sys
from xml.dom import minidom, Node
def getChildren(node):
"Return the child elements of the given XML node"
return filter(lambda child: child.nodeType == Node.ELEMENT_NODE,
node.childNodes)
def getText(node):
""" Returns the stripped text of the given node. Multiple text nodes
are striped and joined by spaced. """
return " ".join( [child.data.strip() for child in node.childNodes
if child.nodeType == Node.TEXT_NODE] )
class Stat(object):
name = ""
description = ""
def __init__(self, node=None):
if node:
self.kind = node.nodeName
self.name = node.getAttribute("name")
self.description = node.getAttribute("description")
def __repr__(self): return self.name
class IntStat(Stat):
value = 0
def __init__(self, node):
Stat.__init__(self, node)
if node:
self.value = int(getText(node))
class FloatStat(Stat):
value = 0.0
def __init__(self, node):
Stat.__init__(self, node)
if node:
self.value = float(getText(node))
class StringStat(Stat):
value = ""
def __init__(self, node):
Stat.__init__(self, node)
if node:
self.value = getText(node)
class TimerStat(Stat):
elapsed = 0.0
user = 0.0
system = 0.0
def __init__(self, node):
Stat.__init__(self, node)
if node:
vals = [float(getText(child)) for child in getChildren(node)]
self.elapsed = vals[0]
if len(vals) > 1:
self.user = vals[1]
self.system = vals[2]
class RangeStat(Stat):
current = 0.0
total = 0.0
min = 0.0
max = 0.0
average = 0.0
count = 0.0
def __init__(self, node):
Stat.__init__(self, node)
if node:
(self.current, self.total, self.min, self.max,
self.average, self.count) = \
[float(getText(child)) for child in getChildren(node)]
class MemoryStat(Stat):
peak = 0
current = 0
def __init__(self, node):
Stat.__init__(self, node)
if node:
(self.peak, self.current) = \
[int(getText(child)) for child in getChildren(node)]
class SetStat(list, Stat):
def __init__(self, node):
Stat.__init__(self, node)
if node:
for child in getChildren(node):
self.append(getText(child))
class HistogramStat(Stat):
labels = []
bins = []
def __init__(self, node):
Stat.__init__(self, node)
if node:
for bin in getChildren(node):
self.labels.append(bin.getAttribute("label"))
self.bins.append(int(getText(bin)))
class StatsList(list, Stat):
def __init__(self, node):
Stat.__init__(self, node)
if node:
nodeTypes = { "int" : IntStat,
"float" : FloatStat,
"string" : StringStat,
"timer" : TimerStat,
"range" : RangeStat,
"memory" : MemoryStat,
"set" : SetStat,
"histogram" : HistogramStat,
"stats" : StatsList }
for child in getChildren(node):
self.append( nodeTypes[child.nodeName](child) )
class StatsDoc(StatsList):
def __init__(self, filename):
docNode = minidom.parse(filename).documentElement
StatsList.__init__(self, docNode)
#include <libxml/parser.h>
#include <libxml/tree.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
static xmlDocPtr doc = NULL;
static void indent(int depth) {
int i;
for (i = 0; i < depth; ++i)
printf(" ");
}
static void printContent(xmlNodePtr node) {
xmlChar* text = xmlNodeListGetString(doc, node->children, 1);
printf("%s", text);
xmlFree(text);
}
/* Get the nth element in a sequence of nodes, ignoring any text nodes. */
static xmlNodePtr nth(xmlNodePtr node, int n) {
while (node) {
if (node->type != XML_ELEMENT_NODE)
node = node->next;
else if (n == 0)
return node;
else {
--n;
node = node->next;
}
}
return NULL;
}
/* Print a structured stat that has simple members. */
static void printStructuredStat(xmlNodePtr node) {
int first = 1;
for (node = node->children; node != NULL; node = node->next) {
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE) {
if (!first) printf(", ");
else first = 0;
/* Print the member name and text. */
printf("%s: ", node->name);
printContent(node);
}
}
printf("\n");
}
/* Forward declaration */
static void printStatsList(xmlNodePtr node, int depth);
static void printStat(xmlNodePtr node, int depth) {
/* Recursively print any nested stats lists. */
if (!xmlStrcmp(node->name, "stats")) {
printStatsList(node, depth+1);
return;
}
/* Print the name of the stat. */
xmlChar* name = xmlGetProp(node, "name");
indent(depth); printf("%s: ", name);
xmlFree(name);
if (!xmlStrcmp(node->name, "int") ||
!xmlStrcmp(node->name, "float") ||
!xmlStrcmp(node->name, "string")) {
printContent(node);
printf("\n");
}
else
printStructuredStat(node);
}
static void printStatsList(xmlNodePtr node, int depth) {
xmlChar* name = xmlGetProp(node, "name");
indent(depth); printf("%s:\n", name);
xmlFree(name);
for (node = node->children; node != NULL; node = node->next)
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE)
printStat(node, depth+1);
}
static void printStatsDoc(xmlNodePtr node) {
for (node = node->children; node != NULL; node = node->next)
/* Ignore text nodes, which contain only whitespace. */
if (node->type == XML_ELEMENT_NODE)
printStatsList(node, 0);
}
int main(int argc, char** argv) {
/* NOTE: error checking omitted for brevity */
doc = xmlParseFile(argv[1]);
xmlNodePtr root = xmlDocGetRootElement(doc);
printStatsDoc(root);
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
}
| Pixar
Animation Studios
|