Dispatching: Job Traversal and Command Launching
The following discussion of Alfred dispatching concepts
is intended as a guide to understanding the basic
job traversal and command launching mechanism at the
heart of Alfred, with specific attention to the
user-selectable dispatching schemes. For details
on creating hierarchical Alfred job scripts, see
the scripting documentation.
The Dispatcher is one of several
Alfred components,
and it is the piece which actually launches and tracks
the commands which make up a job. It also enforces
launch sequences by keeping track
of dependencies. And finally, the dispatcher is responsible
for tracking and reporting errors.
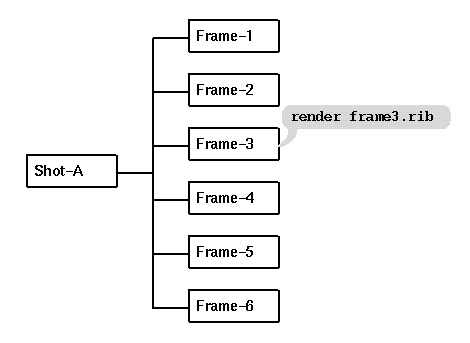
The diagram above illustrates the structure of a simple
rendering job. The shot consists of several frames,
and any actions to be taken at the shot level must wait
for the actions at the frame level to complete first.
In the simplest Alfred job, the frame-level action might
be to invoke the "render" command on an appropriate RIB
file, and there might be no action at all at the shot
level or perhaps it just cleans up the RIB files.
It's clear that if all we wanted to do was render six RIB
files that we could just launch the commands by hand
or write a very simple, linear, shell script which accomplished
this trivially.
Alfred derives almost all of its complexity, and power, from
addressing the following observations:
- most meaningful jobs have a series of dependent stages
- at a given level of hierarchy there are often self-similar
independent task sub-trees
- there are often enough compute resources available to work
on several independent sections of the job in parallel
In the example above, if there were six rendering servers available
on the network we could compute six frames at once, rather than
in sequence. If there were only two remote renderers available
we can still do better than linear time by processing the
frames in pairs.
- a job is the structured collection of actions defined by
a worklist (alfred script).
- a task is an organizational object which is used to
establish the order of execution through dependencies. Syntactically, this
hierarchy is achieved by nesting the task expressions. Tasks are nodes on the
execution tree, and they are processed from the leaves to the root (innermost to
outermost nesting, in depth-first order).
- a command defines a unit of work by naming a program
to be launched and its arguments. Each task contains a list of
commands to execute; a task processes its commands after all of
its sub-tasks have completed their commands.
- a launch-expression is the text of the actual executable
statement to be launched by a particular command. Typically it is the
invocation of some application program, such as netrender. In addition
to command-line (invocation) arguments some applications require, or can accept,
directives as terminal input (stdin); for these cases alfred
commands may define messages which will be piped to the
application once it has been launched.
- persistent applications are those which do not exit
between successive commands; that is, the application is launched once and
during the course of job execution commands send it messages as
required. See the documentation on
alfred compliant applications
for more details.
- services are an abstraction of the remote
server concept. The most common service used by alfred jobs will be
the alfserver, i.e. a remote host running an alfserver which
accepts rendering requests from (local) netrender
client programs. Commands which require a particular
service will be blocked until that service becomes available.
When several dispatchers require the same service, the maitre_d
(service allocation daemon) can be used to globally allocate services
to particular users and arbitrate requests.
- the huntgroup for a particular dispatcher is the
list of services to which it currently has access, as defined by the
schedule. When a job needs a remote server the dispatcher requests
one from the maitre_d. Since each requesting dispatcher may have
access to different sets of servers (disjoint or overlapping), the
maitre_d takes care of prioritizing requests and returning the
first available server to which the requesting dispatcher has
top priority and which is the most "desirable" at the
time of the request.
- jobs are structured as a tree of hierarchies,
there is one link "up" to a parent node, and zero or more links
"down" into child nodes. This is a straightforward
way to represent a system of tasks which might depend on
other (child) tasks being completed first. A Directed Acyclic
Graph (DAG) is a generalization of a strict tree structure.
Alfred jobs are typically simple trees, although the Instance
node type can be used for a simple kind of shared dependence.
- a depth-first traversal strategy is one in which
descent into child nodes occurs as deeply as possible, as quickly
as possible. That is, control descends recursively into a child node,
and returns, before the next (sibling) child node is processed.
Alfred uses this mechanism to find and launch commands (see
the next section).
- a breadth-first traversal strategy descends into
child nodes as broadly as possible before descent into the next
level of the hierarchy occurs. Alfred does not use this
strategy for its various traversals.
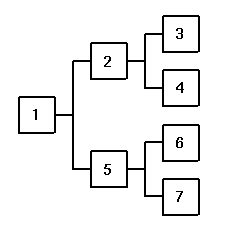 |
 |
| Task Search Order |
Evaluation Order (Sequential) |
Alfred searches its job tree in depth first
order for commands which can be launched. The diagram on the left shows
a simple hierarchy with the nodes numbered in depth-first
traversal order; this is the sequence in which Task nodes are
searched when looking for commands to launch.
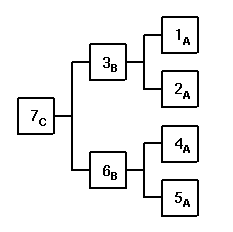
The diagram on the right shows the evaluation order required
to enforce the desired hierarchy of dependencies. The nodes are
numbered assuming that only one can run at a time, this is
strict Task Sequential execution (see below).
If tasks are allowed to execute in parallel, then the
dependency constraints allow the order of evaluation indicated by
the letters: all of the A nodes can execute at the same time,
then the B nodes, and finally C, the root node.
Parallel execution is the default, given enough available resources.
Note: strictly speaking, Alfred only launches one
command at a time; parallel execution occurs because
it doesn't wait for the first task to finish before looking for
another one to launch.
Alfred always searches for launchable tasks in depth-first order,
and it launches the first available leaf node it can find. For
example, assuming that all the nodes above represent approximately
equal rendering tasks, and that we have enough processors to do
two renderings simultaneously, then the execution order might be:
1A and 2A together, then 3B and 4A together, then 5A, then 6B,
then 7C.
Actual launching order is very job-specific since it depends
on how long each task really takes, the actual task dependencies
and the number of processors that become available during the
course of the job.
It is often the case that there are several jobs on the
local dispatching queue at once. Alfred provides a choice
of several dispatching schemes which determine the order
in which tasks from different jobs are processed. The current
dispatching mode is set as a per-user preference from the
Session->Preferences menu.
- Task Sequential: only one task is active at a time.
Commands are launched in the usual depth-first task sequence,
but unlike other modes, tasks are not allowed to run in parallel.
This mode is typically used only during script debugging.
- Job Sequential: each job on the local queue is
processed to completion before any work is done in succeeding jobs.
Jobs are always sorted according to their
priority so that the job with
the highest priority bias becomes active at the top of the queue.
- Job Spill-Over: the top job on the queue is checked for
commands which can be launched; if there are still resources
available, then tasks from subsequent jobs are also considered.
Changes to job priority cause a queue re-sort, as above.
This mode is particularly useful when there are jobs on the
queue which require non-competing resources, such as jobs doing
different kinds of work or jobs with non-overlapping
huntgroups. It also provides
the most efficient behavior near the end of a job when there
are fewer and fewer opportunities for parallel execution; in
spill-over mode the succeeding job can start to use the unneeded
processors before the first job is finished.
In situations where there are only a small number of
available processors, and job hierarchies are relatively deep,
and frame times are long, spill-over mode can sometimes produce
a situation in which a secondary job "steals" a temporarily
unused processor from the primary job for a long time. Also,
persistent applications
are not shared between jobs, so this mode can sometimes
produce a heavier clienting load; use limits
to reduce this effect.
- Job Parallel: each job on the queue is active, and they
compete for resources independently, according to priority and
requirements. The effect is almost as if each job had its own
dispatcher, which can lead to a single user "flooding" the
maitre-d queue, and is typically not a very efficient use of the
clienting host (see the caveats above). This mode is useful in
certain high-performance situations.
In general, Spill-Over mode will be the most efficient, and it is
the default. At some sites, system administrators may want to
enforce a uniform dispatching scheme across all users. See the
notes on LOCKing user preferences in the alfred.ini file.
During job traversal alfred will determine which Tasks are ready to
be processed. A task becomes ready to execute when all of its
dependencies have been met, which means that all of its subtasks
have completed successfully.
Each non-trivial Task contains
Cmd
descriptions which describe the actual applications to be launched.
When a Cmd is found in a Ready Task, it may not be executed
immediately, especially if it requires a scarce resource such
as a remote rendering server. The dispatcher contacts the
the maitre-d to check-out resources and acquire the final
launch clearance.
When the required checks are cleared, the actual command launch
and subsequent process tracking involves these steps:
- the names of any required remote servers are obtained from the maitre_d
- runtime values (like remote host names) are
substituted into the expression
- the resulting string is tokenized (split into words at blanks, except
where a multi-word token is contained in {})
- a new process is created using fork(2)
- the process is put in its own process-group (session) using setsid(2)
- the application program is executed using execvp(2)
- alfred maintains pipes to the app's stdin, stdout, & stderr
(which consumes three file descriptors, see sysconf(1) and the 'limit'
shell built-in command).
- after launch, any input -msg text is piped to the app's stdin
- process status is monitored via the pipes and waitpid(2)
- the Pause button causes SIGSTOP (or SIGCONT)
to be sent to the process
- running commands can be interrupted: task restart or job deletion
causes the following sequence of steps to be applied until
the process exits: close stdin; send SIGTERM; send SIGKILL.
Note: the shutdown signals are sent to the command's process-group, which
means that they will be delivered to any child processes (of the command)
as well.
- if the process exit status is non-zero, as determined by
waitpid(2), it is considered to have had
an error, and execution of the affected subtree is blocked;
an exit status of zero indicates successful completion,
and the enclosing Task is marked "Done".
As just noted, when a launched command exits with a
non-zero exit status, it is considered to have had an
error. Referring again to the numbered task diagram above,
if the command launched by task "3B"
encounters an error, it will stop execution and indicate
the error; also any output diagnostics generated by the
command will be made available.
Note that the entire job might not stop
when an error occurs. If there are other ready tasks
which do not depend on the stopped error task, then they
can continue as usual. There is a toggle-switch on
the Session->Preferences panel which controls
whether this kind of parallel processing continues after
an error occurs.
Eventually, all that will remain will be the task with the
error and its parent tasks which depend on it. At this point the
job won't be able to proceed any farther, and it will enter the
Error-Wait state. If the dispatching
scheme is Spill-Over or Parallel then
other jobs on the local queue will begin to run; if the scheme
is Sequential then the entire job queue will also wait.
Tasks with errors can either be manually
restarted or skipped. If
automatic retries have been enabled
on the Session->Preferences control panel,
then the dispatcher will attempt to re-launch the
command a fixed number of times.
Jobs can be deleted simply by clicking on their entry in the Job Queue
window and pressing the Backspace or Delete keys, or selecting
Delete Job from the menu.
When currently active jobs are
deleted, all of their active tasks are terminated and clean-up commands
along DAG paths containing active tasks are executed. Also, by default,
a dialog appears asking to confirm that you really want to delete an
active job; this dialog can be disabled if desired.
There is also an
automatic job deletion preference setting
which will automatically delete done jobs or maintain a short list of the
most recently completed jobs while deleting older ones.
When a job is deleted, all output logs and status information are also
deleted, therefore it is sometimes useful to retain jobs until you've
had a chance to look for unusual output. Job can be browsed from
either the Job Detail Window or via
the web interface, both of which rely on a
running dispatcher to supply status information.
By default, the dispatcher doesn't exit until all jobs have been deleted
from the Job Queue. This conservative approach ensures that job status
information is available for done and active jobs until a person chooses
to delete the jobs. The dispatcher will therefore continue to run, even
when all the user interfaces have been closed. Alternatively, there is a
preference setting which specifies that the dispatcher should delete all
done jobs when the last UI closes, and it can therefore shutdown as well.
Pixar Animation Studios
(510) 752-3000 (voice)
(510) 752-3151 (fax)
Copyright © 1996-
Pixar. All rights reserved.
RenderMan® is a registered trademark of Pixar. |